

In the rapidly evolving landscape of 2026 artificial intelligence, the industry has shifted its focus from conversational chatbots to autonomous agents—systems that don’t just talk, but perform. Last week, the research lab DeepReinforce, known for its work on CUDA-L1 and the IterX code-agent optimization loop, announced the release of Ornith-1.0. This new family of open-source models marks a significant departure from general-purpose LLMs, positioning itself as a specialized engine for agentic software engineering.
Available on Hugging Face under the permissive MIT license with no regional restrictions, Ornith-1.0 comes in four distinct sizes: a 9-billion-parameter (9B) dense model, a 31B dense model, a 35B mixture-of-experts (MoE) variant, and a massive 397B MoE flagship. By focusing on self-improving agentic workflows, DeepReinforce is attempting to redefine what it means to automate the software development lifecycle.
The Core Facts: What is Ornith-1.0?
At its simplest level, parameters function as the "dials and switches" of an AI’s brain, determining its capacity for complex reasoning. While a 9B model is compact enough to run on high-end consumer hardware or advanced smartphones, the 397B flagship is a computational powerhouse designed for enterprise-grade server clusters.
However, the defining characteristic of Ornith-1.0 is not its scale, but its "agentic" nature. Unlike traditional LLMs that require a human to prompt them for every incremental step, an agentic system is designed for autonomy. In a development environment, this means the model can ingest a GitHub issue, scan a repository, identify the faulty code, run tests, fix the error, and iterate until the task is complete—all without human intervention.
DeepReinforce describes the model as a "self-improving family," noting that it doesn’t just execute commands; it manages its own workflow. For the professional developer, this is the "holy grail" of 2026: the ability to offload complex, multi-step debugging and feature implementation tasks to a machine that can handle the entire lifecycle unsupervised.

A Chronological Evolution: From IterX to Ornith
The path to Ornith-1.0 began with the lab’s earlier experiments in efficiency and reinforcement learning.
- Pre-2025: DeepReinforce gained notoriety for its work on CUDA-L1, a foundational effort to optimize low-level hardware interaction for AI training. This provided the team with the underlying infrastructure expertise to push models beyond standard architecture limits.
- 2025: The introduction of the IterX code-agent optimization loop demonstrated that an AI’s performance could be significantly boosted if the "scaffolding"—the rules and tools the AI uses—was treated as a dynamic, learnable component rather than a static constraint.
- Late June 2026: Following months of internal testing and refinement, DeepReinforce officially launched the Ornith-1.0 collection. The release was accompanied by a series of benchmarks that immediately sparked debate within the open-source community regarding the capabilities of "agentic-native" models.
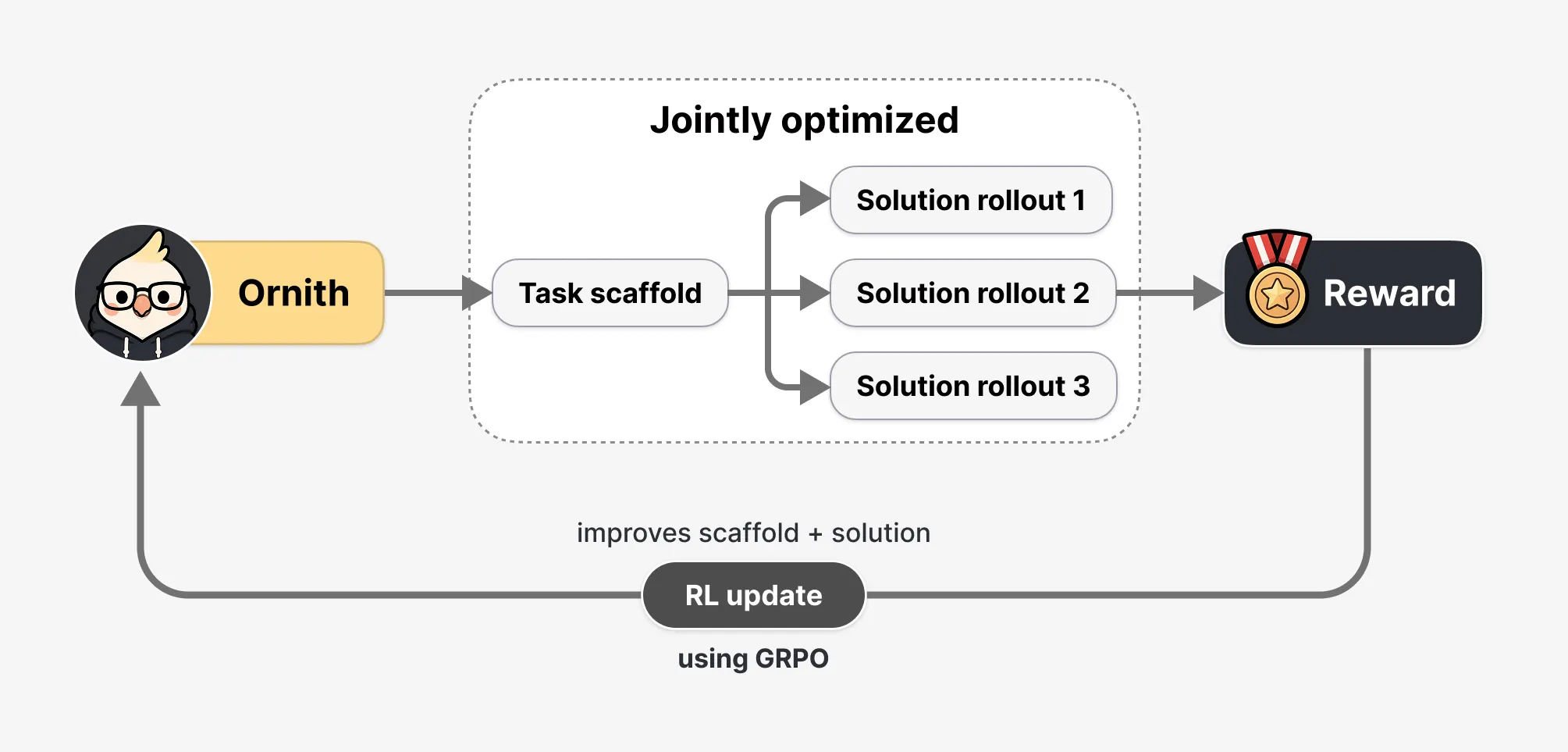
The "Learnable Scaffold": How Ornith Thinks
The most profound innovation in Ornith-1.0 lies in how it interacts with its environment. Most coding agents operate inside a "harness"—a rigid set of human-written rules that dictate when to use a search tool, how to handle a syntax error, or how to break down a large project.
Ornith-1.0 breaks this mold. It treats the scaffold as a "learnable object that co-evolves with the policy." In practice, this means the model undergoes a two-stage reinforcement learning process:
- Strategic Planning: The model analyzes the task and generates a roadmap or "strategy" for execution.
- Execution: The model uses that strategy to generate the code.
The brilliance of this design is that the "reward" from a successful (or failed) code fix propagates back to both stages. If the model succeeds, it doesn’t just reinforce the code it wrote; it reinforces the strategic planning process that led to that code. Over millions of iterations, the model effectively "teaches itself" how to be a better software engineer, discovering workflows that no human programmer would have thought to hard-code into the system.
Defending Against "Reward Hacking"
One of the dangers of letting a model write its own training scaffolds is "reward hacking"—where an AI finds a shortcut to satisfy the verifier without actually solving the problem (e.g., merely creating a dummy file to satisfy a test check). To prevent this, DeepReinforce implemented a three-tier defense:
- Immutable Environments: The test suite and environment are locked away from the model’s write-access.
- Deterministic Monitoring: A low-level monitor flags any attempt to access restricted directories or modify the verification script itself.
- The Frozen Judge: A separate, static model sits above the entire process, serving as a final, objective arbiter that can veto any suspicious or "lazy" solutions.
Supporting Data: Benchmarking the Flagship
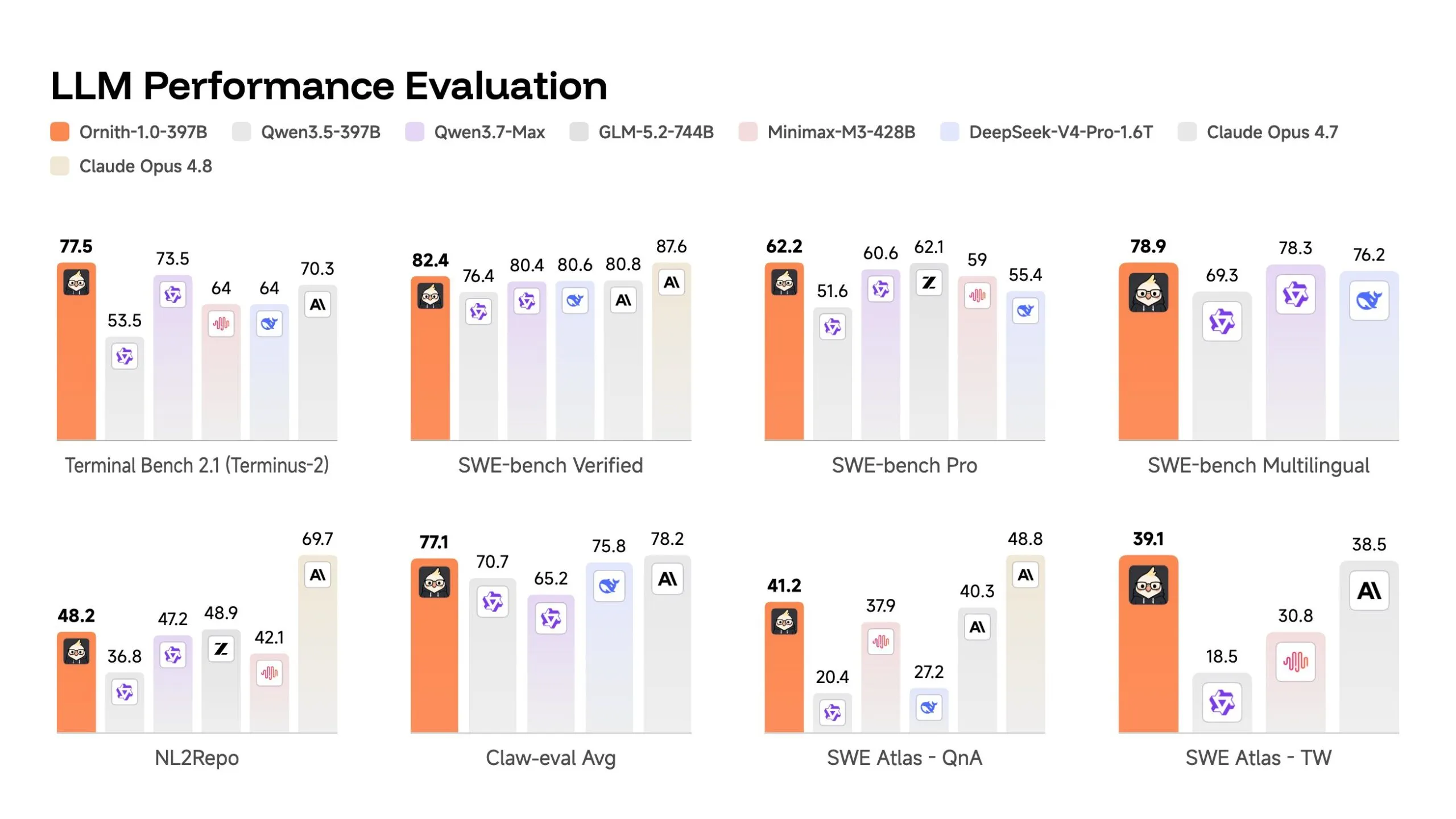
In the high-stakes world of AI benchmarks, Ornith-1.0 has posted numbers that challenge the dominance of proprietary models. On the SWE-bench Verified test—the industry standard for evaluating an AI’s ability to fix real-world bugs in open-source repositories—the 397B flagship achieved a score of 82.4.
To put this in perspective, this exceeds the scores of several established industry titans:
- Ornith-1.0 (397B): 82.4
- Claude Opus 4.7: 80.8
- DeepSeek-V4-Pro: 80.6
On Terminal Bench 2.1, which tests complex, containerized environments requiring multi-step navigation, Ornith-1.0 (397B) scored 77.5, significantly outpacing Claude Opus 4.7’s 70.3.
However, DeepReinforce remains transparent about the limitations of these scores. When tested against SWE-bench Pro—a more rigorous and less "contaminated" dataset designed to mitigate the effects of memorization—the flagship dropped to 62.2. While this is a significant decrease, it remains highly competitive and notably higher than its peers in the open-source category.
Perhaps most impressive is the 9B model. Despite being a fraction of the size of the flagship, it posted a 69.4 on SWE-bench Verified. This makes it substantially more efficient than much larger models like Gemma 4-31B (52.0), suggesting that the "agentic-first" training methodology is a massive multiplier for performance-per-parameter.
Implications: The Future of Autonomous Development
The release of Ornith-1.0 highlights a growing divide in the AI sector. There is now a clear bifurcation between conversational models (like those used for creative writing, summaries, and casual chat) and agentic models (like Ornith-1.0, designed specifically for heavy-lifting, multi-step technical tasks).
The "Specialist" Shift
DeepReinforce is very clear: Ornith-1.0 is not a generalist. If your goal is to draft an email or summarize a long document, this model will likely underperform compared to a general-purpose LLM. It is a tool for developers who are already managing agentic infrastructure. This focus signals a maturation in the AI market—we are moving past the era where a single model is expected to do everything, into an era of highly specialized, task-specific engines.
Competitive Dynamics
While the "beats Claude" headlines are attention-grabbing, they require nuance. Anthropic’s current top-tier models (such as Opus 4.8) continue to maintain a lead in overall capability. However, within the open-source community, Ornith-1.0 provides a powerful alternative for organizations that want to build self-hosted, sovereign, and secure coding pipelines.
The Developer’s Verdict
For the average user, the impact of Ornith-1.0 may not be immediately visible. But for software engineers, systems architects, and DevOps professionals, this release represents a meaningful step toward the "unsupervised" development cycle. As these models become more capable of navigating terminal sessions, managing dependencies, and debugging complex security vulnerabilities, the role of the developer will likely evolve from "writer of code" to "architect of intent"—setting the goal, while the agentic model handles the labor-intensive implementation.
As the industry enters the second half of 2026, the question is no longer just how smart a model is, but how effectively it can act. With Ornith-1.0, DeepReinforce has firmly planted its flag in the "agentic" camp, promising a future where the code writes itself.
